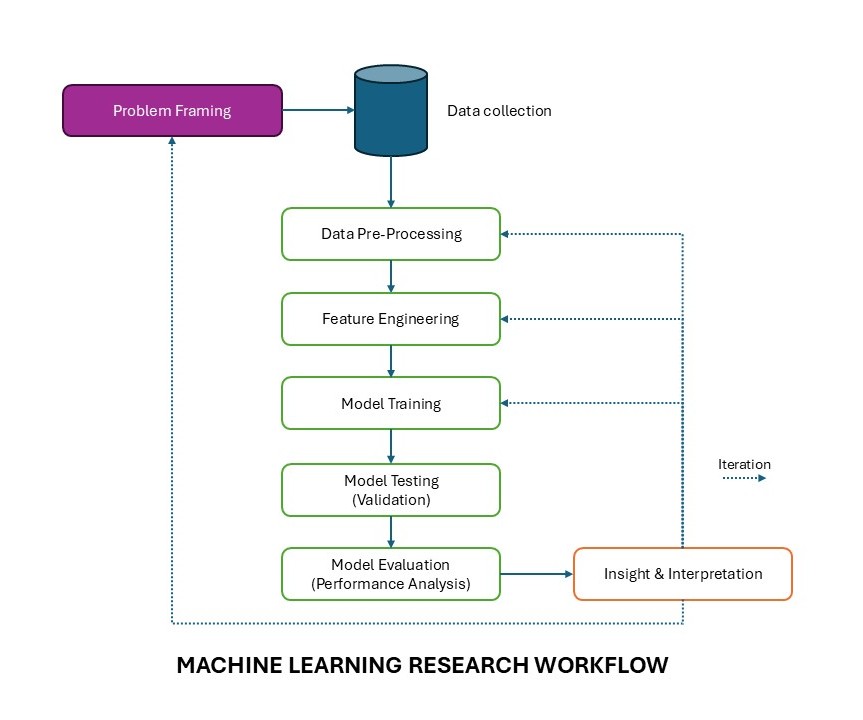
Using Problem Framing as a guide, students can now construct Problem Statement & Justification in the Research Background section of the Research Proposal Template.
1. Problem Statement & Justification
The research problem is the foundation of your entire proposal. It clearly defines the issue or gap in knowledge that your study aims to address. Use your Problem Framing as reference to write a strong problem statement and justification:
Paragraph 1 – Provide Context: Start by pinpointing a specific real-world issue, challenge, or question within your chosen field.
Paragraph 2 – Highlight the Gap: Show where current understanding falls short or where there are conflicting viewpoints. Provide limitations of current methods with proofs.
Paragraph 3 – The Justification: Demonstrate why this issue is important and why existing knowledge is insufficient. Justify the current approach, including why the application Machine Learning is needed.
2. Research Questions
Research questions are the cornerstone of your research project. They act as a roadmap, guiding your investigation and focusing your analysis. Here’s how to craft effective research questions for your proposal:
a. Main Research Question
Your main research question should stem directly from the problem statement you identified and derived from your problem framing. It should be specific and directly address the gaps in knowledge you highlighted.
b. Sub-questions
Provide 2-3 smaller questions that help you answer the main question. Frame your questions in a concise and clear way. Avoid ambiguity and ensure they can be answered through your chosen research methods and data you plan to collect.
Make sure your questions are measurable and feasible within the scope of your project.
By following these guidelines, you can develop strong research questions that will guide your research and ensure a well-focused proposal. Remember, your research questions should spark curiosity, provide direction, and ultimately lead to valuable insights!
3. Research Objective and Hypothesis
a. Main Objective
The main objective is the goal of your research project. It’s a broad statement that captures the general direction of your investigation and answerable to the Main Research Question.
b. Specific Objectives
Specific objectives break down the main objective into smaller, more manageable steps and answerable to Sub-questions. They outline the concrete actions you’ll take to achieve your overall goal. Specific objectives should be SMART (Specific, Measurable, Achievable, Relevant, and Time-bound).
c. Hypothesis
A hypothesis is a specific prediction about the outcome of your research. It’s an educated guess based on existing knowledge or theories. Not all research projects require a hypothesis, particularly exploratory studies.