This framework presents machine learning research as an iterative scientific process rather than a one-way technical pipeline. Each step contributes to how a research problem is translated into data, models, and eventually meaningful insight. Researchers are advised to use this framework as basis to research methodology.
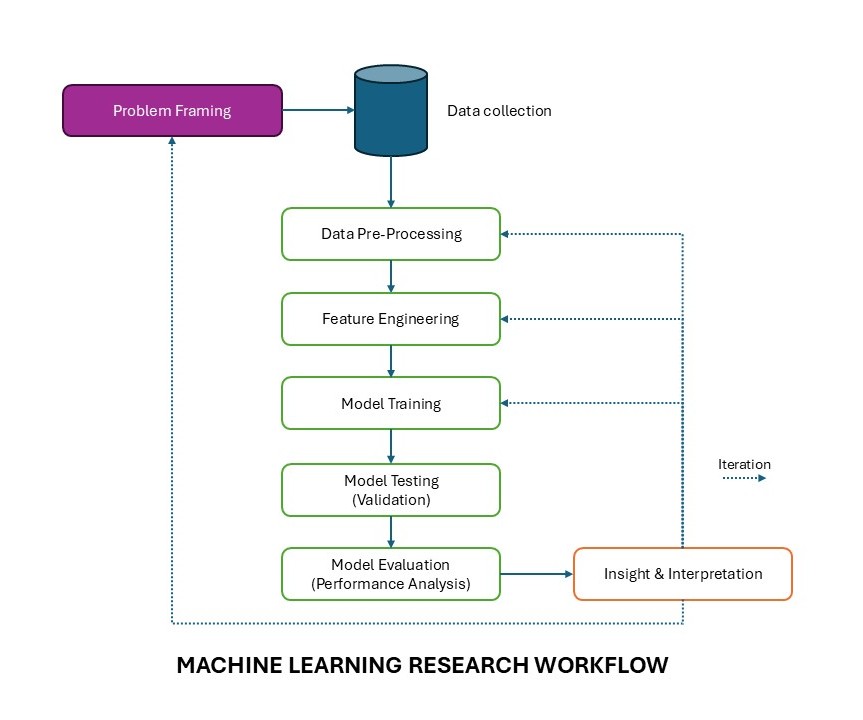
1. Problem Framing
Problem framing is the starting point of the research. At this stage, the researcher defines the core question that the study aims to address and translates it into a machine learning problem. This includes identifying the prediction target, determining whether the task involves classification, regression, or both, and clarifying the real-world purpose of the study. A well-framed problem ensures that the later stages of data handling, modeling, and evaluation remain aligned with the actual research objective.
2. Data Collection
Once the problem is defined, relevant data must be collected. This step involves gathering the observations, measurements, and images, that will be used in the study. The quality and representativeness of the dataset are critical, because machine learning models learn patterns directly from the data provided. Poorly collected or biased data will affect every later step, regardless of how sophisticated the model is.
3. Data Pre-Processing
Data pre-processing prepares the dataset for analysis by cleaning errors, handling missing values, normalizing or resizing inputs, organizing labels, and transforming the data into a suitable format. In image-based studies, for example, this may include cropping, scaling, grayscale conversion, contrast adjustment, or background removal. This step improves consistency and helps reduce unwanted variation that may interfere with learning.
4. Feature Engineering
Feature engineering refers to the process of extracting, selecting, or constructing informative representations from the pre-processed data. In conventional machine learning, this may involve manually defining measurements such as length, area, texture, or shape descriptors. In deeper learning workflows, it can also involve choosing image representations or latent features that better reveal meaningful structure. This step is important because the way data are represented can strongly influence how well a model can learn useful patterns.
5. Model Training
Model training is the stage where the algorithm learns from the training data. During this process, the model adjusts its internal parameters so that it can map input data to the intended output. The training step depends on the problem type, the chosen algorithm, and the structure of the data. At this stage, the goal is not only to fit the data but to learn patterns that can generalize beyond the examples already seen.
6. Model Testing (Validation)
After training, the model must be tested on data that were not used during learning. This helps determine whether the model can generalize to new cases rather than simply memorizing the training set. Validation provides an intermediate assessment of model behavior and allows the researcher to monitor overfitting, compare alternative configurations, and decide whether further refinement is needed. In research practice, this step acts as an important checkpoint before final evaluation.
7. Model Evaluation (Performance Analysis)
Model evaluation examines how well the trained model performs using appropriate metrics and analytical criteria. The specific evaluation approach depends on the research objective. Classification studies may use accuracy, precision, recall, or F1-score, while clustering studies may use silhouette score or Davies–Bouldin index, and regression studies may use RMSE or MAE. In research settings, this stage may also include robustness checks, statistical comparison, and other analyses to determine whether the observed performance is stable, meaningful, and scientifically defensible.
8. Insight and Interpretation
Machine learning research should not end with numerical performance alone. The final step is to interpret what the results actually mean in relation to the research question. This may involve identifying why one representation performs better than another, understanding which features contribute most to the outcome, or explaining how the findings relate back to the scientific or applied problem. Insight and interpretation transform model output into research knowledge.
The dashed arrows in the diagram represent iteration, which is one of the defining characteristics of machine learning research. Results from evaluation and interpretation often lead the researcher back to earlier stages such as pre-processing, feature engineering, model design, or even problem framing itself. This means the workflow is not strictly linear. Instead, it is a cycle of refinement in which each round of analysis improves understanding of the data, the model, and the research question.